
From Aristotle to Artificial Intelligence: How the Sudden Intersection of Philosophy, Computing Power, and Algorithms Transformed the Future of Intelligence

How did we “suddenly” get to the boom of Artificial Intelligence (AI) we live in? Artificial Intelligence is far from a recent or sudden invention. Powering everything from chatbots to self-driving cars, its origins trace back centuries. Like many of humanity’s most significant and historic innovations, AI emerged from the power of relentless curiosity — the same force that has long driven mankind to explore profound philosophical questions at the intersection of logic, human nature, and innovation.
Its evolution has been shaped by three foundational forces simultaneously converging circa 2012: (1) centuries of philosophical inquiry, (2) computing power hardware advancements, and (3) algorithmic breakthroughs. These three forces, developing in parallel over time, laid the groundwork for the AI-driven world we see today.
In the following discussion, we will trace the historical arc of these three pillars — philosophy, hardware, and algorithms — and explain how we at Hudson Hill and BlueCloud are leveraging and implementing AI to create real-world impact across our portfolio companies — an impact that you too can emulate in your own business.
Philosophical Foundations of AI: Aristotle, Descartes, Leibnitz, & Turing
Long before computers existed, some of history’s greatest thinkers pondered the nature of intelligence. Aristotle (384–322 BC) laid the groundwork with formal logic, a structured approach to reasoning that still underpins AI algorithms today. Centuries later, René Descartes (1596–1650) introduced the idea of mind-body dualism and mechanistic processes, sparking early debates about whether machines could replicate human cognition. He proposed that certain functions of human thought could be mechanized, a notion that influenced philosophical discussions on artificial cognition and, ultimately, artificial intelligence.
In 1689, Gottfried Wilhelm Leibniz (1646–1716) advanced this idea further by developing the binary system, which centuries later would become the core foundation of computing — and, ultimately, artificial intelligence. At its core, binary relies on just two digits — 0 and 1 — known as bits. A combination of bits forms bytes (8 bits), which, in simple terms, constitute the code computers process to understand information, and are a fundamental component of computer hardware. These bits and gates perform essential logical operations needed to represent data, commands, and instructions, encoding everything from numbers and text to images — forming the very basis of modern computation and AI.

Each word we write digitally is ultimately translated back to the binary code — a series of 0s and 1s — that represent a hardware command for the computer (explained more throughout article)
The 20th century marked a turning point with Alan Turing (1912–1954), who, in 1936, demonstrated that machines could process information and solve problems similarly to humans. His Turing Machine established binary logic as the bedrock of digital computation. At the same time, his famous Turing Test, still relevant today, set the ultimate benchmark for AI: creating machines that are indistinguishable from human intelligence.
Turing’s trailblazing work in code breaking during World War II pioneered techniques based on pattern recognition — laying the foundation for modern machine learning and shaping the future of artificial intelligence.

Alan Turing

Gottfried Wilhelm Leibniz
Post WWII Hardware Revolution: Data + Model + Computing Power = AI
In 1947, William Shockley and his colleagues at Bell Labs invented the transistor, a semiconductor device that revolutionized electronics by replacing bulky vacuum tubes with smaller, more efficient semiconductor materials like silicon. Silicon, which has properties that lie between conductors (metals) and insulators (rubber), possesses a unique ability to control electrical currents under certain conditions (fun fact: this is where the name Silicon Valley comes from).

William Shockley
Transistors were compact, reliable, and consumed less power, functioning as switches or amplifiers to regulate electrical signals. The switching of electric currents between ON (1) and OFF (0) is what enables computers to read and compute binary code. This breakthrough led to the miniaturization of computers, paving the way for microprocessors, digital logic, and storage devices, ultimately transforming modern computing.

Transistor (Left) that transmits electric charge Binary Logic of 0s and 1s

By the 1950s and 1960s, the invention of the integrated circuit (IC) took this advancement even further. ICs combined multiple transistors onto a single semiconductor chip, making computers and other electronics more efficient, compact, and powerful. ICs enabled electronics to become wireless, shaping the cultural landscape of the era and subsequent decades.

Transistor composing an Integrated Circuit
In 1965, Gordon Moore made a groundbreaking prediction — now known as Moore’s Law — stating that the transistor density on ICs would double approximately every two years, driving exponential growth in computing power. This principle has held true for decades, fueling hardware advancements in AI chipmaking, data processing, and digital technology.
In 1971, Ted Hoff and his team at Intel created the first commercially available microprocessor, the Intel 4004 — a computer the size of a fingertip — capable of processing requests independently and efficiently. It was a 4-bit process originally designed for use in a calculator, but it laid the foundation for the development of personal computers and modern electronics.

What made the Intel 4004 revolutionary was its ability to integrate the central processing unit (CPU), memory, and input/output control into a single chip. For the first time, computers could be small and affordable enough to fit on a desk, opening the door for mass adoption. This breakthrough ultimately led to the rise of companies like Microsoft and Apple — now two of the richest and most influential companies in the world.

In recent years, since the commercial advent of AI to the average consumer via OpenAI, we have gained a deeper understanding of the critical role of chipmaking in fueling computing power. This brings us to one of the most fundamental components of computing power: the invention of the Central Processing Unit (CPU).
Modern Hardware as the Backbone of AI: The CPU (1971), GPU (1999), & TPU (2016)
Central Processing Units (CPU): The Computer Brain
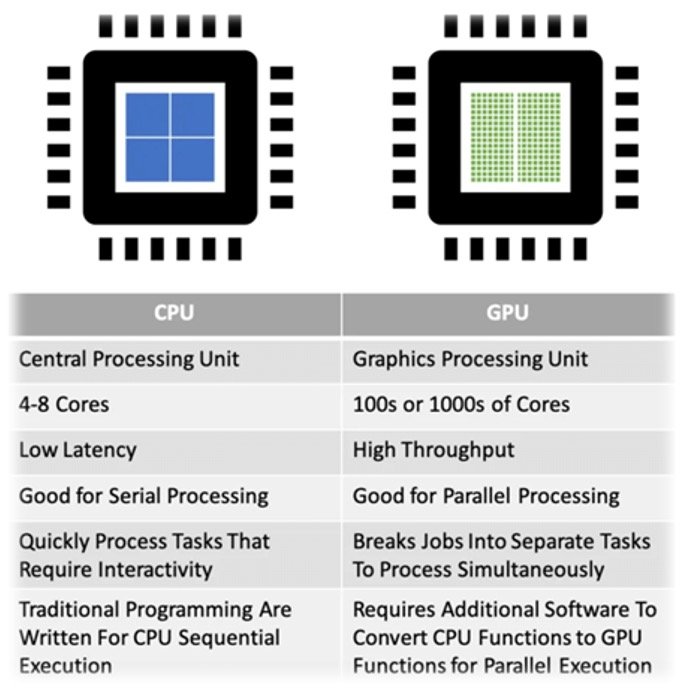
The CPU is the primary component of a computer or electronic device responsible for executing instructions and processing data. Often referred to as the “brain” of the computer, it handles commands from both hardware and software, enabling the system to function efficiently.

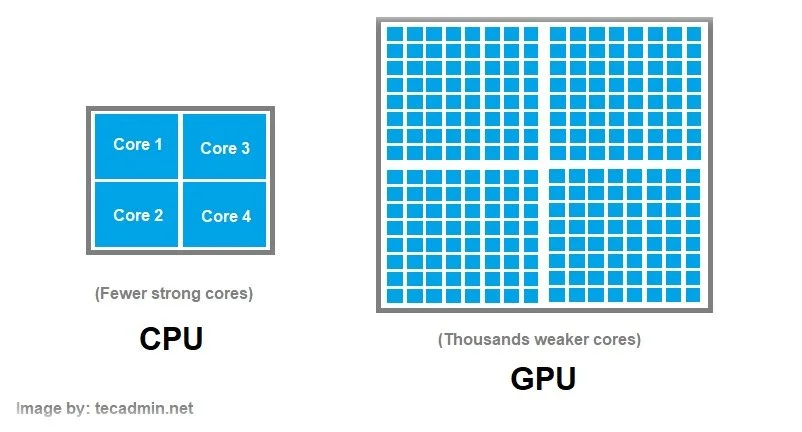
Imagine a CPU core as a worker in a factory with multiple workstations, where each workstation represents a core. If the factory has only one workstation, it can process only one task at a time, slowing production. However, by adding more workstations (CPU cores), multiple tasks can be completed simultaneously, significantly increasing efficiency. The evolution of multi-core processing significantly improved computational speed and efficiency, particularly for workloads that require handling vast amounts of data in real time. However, despite this tremendous advancement, the computing power of the CPU was not sufficient to compute and process the magnitude of information necessary to fuel artificial intelligence.


The 2000s: NVIDIA Graphic Processing Units (GPU) & the Rise of Computational Power, and the Acceleration of AI
The real breakthrough in computing began with the rise of NVIDIA GPUs in the early 2000s. They were originally designed to develop high-performance graphic processors for the gaming industry, powering and rendering the graphics of PlayStation, Xbox, and high-end PCs. Unlike CPUs, which are designed for general-purpose sequential computing, GPUs (Graphics Processing Units) specialize in parallel processing, ultimately making them essential for AI, machine learning, and deep learning. With thousands of cores working simultaneously, GPUs can far outperform traditional CPUs in computationally intensive tasks like training AI models and rendering graphics. While before GPU acceleration, training complex AI models was painfully slow, often taking weeks or months, the introduction of GPU-powered deep learning drastically reducing training times, enabling rapid breakthroughs in computer vision, speech recognition, and natural language processing (NLP). Suddenly, AI was no longer just a theoretical pursuit, but a practical reality.

A pivotal moment thus came in 1999, when NVIDIA introduced the GeForce 256, the first processor to be labeled a GPU. Originally built for gaming graphics, it unexpectedly laid the groundwork for parallel computing in AI. As researchers explored its capabilities beyond rendering images, it became clear that GPUs had the power to revolutionize computing itself. This discovery set NVIDIA on a path beyond gaming, positioning it as a leader in AI-driven computing, and ultimately as one of the most valuable companies in the world, becoming the second company in history to reach a market cap above $3.5 trillion in 2024.
The true breakthrough, however, came in 2006 with the launch of NVIDIA CUDA (Compute Unified Device Architecture). CUDA allowed developers to harness the power of GPUs for general-purpose computing and revolutionized the landscape of AI research by allowing deep learning models to scale efficiently. It was this shift that enabled the development of self-driving technology, real-time translation, and the large-scale AI models that define today’s digital ecosystem. This would become the perfect set up for the 2012 “Big Bang of AI”… but I will get to that later.
2016: Google’s TPUs — The AI Chip Bet That’s Paying Off
As artificial intelligence accelerated, the hardware powering AI models became just as critical as the software driving them. While much of the AI boom has been fueled by advances in machine learning algorithms, the immense computational power required to train today’s models has forced companies to rethink their infrastructure. In 2016, Google introduced its Tensor Processing Units (TPUs) — custom-designed chips built specifically for AI workloads that represent the company’s most ambitious bet yet on optimizing machine learning at scale.
TPUs are Google’s response to the growing demand for AI-specific hardware acceleration; they optimize tensor operations, the core mathematical calculations behind neural networks, and leverage systolic arrays — a specialized type of parallel processing that dramatically increases efficiency in handling complex matrix multiplications. The result? Faster AI model training, lower energy consumption, and reduced operational costs for companies running large-scale machine learning.
The rise of massive AI LLM models — such as OpenAI’s GPT-4, Google’s PaLM, and Meta’s LLaMA — has driven an explosion in computational demand. Training these models requires vast amounts of processing power, often spread across thousands of servers for weeks or months. TPUs dramatically reduce training times, cutting costs and improving efficiency — an increasingly critical advantage as AI becomes more deeply embedded in business operations. More recently, TPUs have become a key selling point for Google Cloud, where enterprise customers can rent TPU clusters to train their own machine learning models.
Algorithms: Powering the Logic and Learning Behind AI
Algorithms represent the last, and third, part of the secret sauce that made artificial intelligence possible. An algorithm is a systematic set of instructions designed to accomplish a specific task or solve a problem by processing input and producing an output. In computer science, algorithms serve as the backbone of programming and computation, guiding how problems are solved efficiently. A simple way to understand an algorithm is to compare it to a recipe — just as a recipe provides step-by-step instructions to prepare a dish, an algorithm provides structured steps for a computer to execute a task. In the realm of AI, algorithms are fundamental for learning patterns, making decisions, and optimizing performance. They power everything from speech recognition and image processing to autonomous driving, machine learning, and predictive analytics. Without algorithms, AI systems would lack the ability to recognize patterns, adapt to new data, or optimize processes, which makes them indispensable for modern computing and automation.
The Blueprint of AI Algorithms: Neural Networks (1950–1960)
Artificial intelligence remained philosophical until the 1950s and 1960s, when scientists began developing neural networks — mathematical models inspired by how the human brain processes information. This era marked the beginning of AI as a computational field, shifting from philosophical speculation to practical experimentation.

During this period, Marvin Minsky, a PhD candidate at Princeton, pioneered the first artificial neurons using wires and six vacuum tubes. This development laid the foundation for neural networks, an approach in artificial intelligence that enables computers to process data in a manner inspired by the human brain. However, it’s important to note that while neural networks are influenced by biological neural structures, they do not directly replicate how the brain works. Instead, they adopt high-level computational principles observed in biological cognition to perform pattern recognition, classification, and decision-making tasks.

A neural network is thus a type of machine learning algorithm designed to recognize patterns, make predictions, and classify data by learning from examples. It consists of interconnected processing units called neurons (or nodes) that transform and connect input data into meaningful insights through multiple layers of computation.

To better understand the concept of neural networks, which is heavily rooted in statistics, I will make the analogy of detectives attempting to solve a crime scene:
Input Layer (Collecting Data — Statistical Distribution & Probabilities): Collects raw data (e.g., images, text, numbers), similar to detectives gathering clues at a crime scene. The raw data (images, text, numbers) can be viewed as samples drawn from an underlying probability distribution. Each input feature has a probability distribution that the network learns to model.
Hidden Layers (Pattern Identification — Feature Transformation & Weight Optimization): Identifies patterns, filtering and analyzing information like detectives examining different pieces (layers) of evidence. The layers apply weighted sums (linear combinations) of inputs followed by nonlinear transformations (activations), which is similar to regression analysis. These weights are adjusted using gradient descent to minimize prediction errors, a process rooted in maximum likelihood estimation (MLE) and Bayesian inference.
Deep Learning (Pattern Connection — Statistical Inference): Connects patterns to draw conclusions, similar to detectives solving a case. The network essentially builds probabilistic models to make inferences. Techniques like backpropagation optimize weights based on loss functions, often derived from statistical methods like cross-entropy (for classification) or mean squared error (for regression). The deeper layers learn hierarchical representations, similar to factor analysis or hidden Markov models.
Output Layer (Predictions — Probability & Decision Theory): Produces final predictions, such as recognizing a face or translating text. Many networks output probability distributions. Decision thresholds (e.g., “if probability > 0.5, classify as X”) rely on statistical decision theory to balance precision and recall.
In short, neural networks are the footprint for artificial intelligence algorithms and they model probability distributions, estimate parameters using optimization, and make inferences based on statistical decision-making principles. They’re essentially complex function approximators that use large-scale statistical learning to generalize patterns from data.
Geoffrey Hinton: The Godfather of AI

Geoffrey Hinton — The Godfather of AI
Let me introduce to you the Godfather of AI — Geoffrey Hinton — a title earned through his groundbreaking work in neural networks and deep learning. In the 1980s, while mainstream AI research focused on rule-based systems, Hinton championed connectionist models, believing that computers could learn the way humans do — by identifying patterns and improving through experience — a concept essential for machine learning. In 1986, he introduced backpropagation, a revolutionary algorithm training method that allowed neural networks to learn from their mistakes and refine their predictions over time (i.e., think Chat GPT or a robot learning from mistakes the more you train it).

Before backpropagation, neural networks struggled with scalability and accuracy, making them impractical for real-world applications. Hinton’s breakthrough changed that by introducing a way for networks to adjust their internal parameters (weights and biases) systematically. Using a technique called gradient descent, backpropagation enables neural networks to minimize errors by calculating how much each neuron contributed to a wrong prediction and adjusting it accordingly. This iterative learning process made deep neural networks far more powerful and efficient, paving the way for modern AI applications, from speech recognition and image classification to natural language processing and autonomous systems.
In short, one can think of backpropagation as a feedback system that helps a neural network learn from its mistakes and improve over time. Here’s how it works in simple terms:
The Network Makes a Guess: Imagine you’re teaching a neural network to recognize whether a picture is of a cat or a dog. The network analyzes the image and makes a guess, saying it’s 70% sure it’s a cat and 30% sure it’s a dog.
Check the Accuracy: Now, you compare the guess with the correct answer. If the image was actually a dog, the network made a mistake. The error is the difference between the guess and the actual label.
Send the Error Back: The mistake is then sent backward through the network (hence the name backpropagation). The network retraces its steps, layer by layer, identifying which internal settings (weights) led to the mistake.
Fix the Weights: The network adjusts the statistical weights responsible for the error. If it was too confident about the cat, it will reduce that confidence and increase its ability to recognize a dog next time.
Repeat and Improve: This process happens thousands or even millions of times with more data. Each time, the network fine-tunes its settings, gradually becoming more accurate and reliable at making predictions.

Robots Self-Teaching to Play Soccer through Machine Learning
Hinton’s persistence in advancing neural networks — despite decades of skepticism — ultimately paid off. His research led to major AI breakthroughs, especially in the 2010s, when deep learning trained with backpropagation outperformed traditional machine learning methods. Today, almost every advanced AI system, from ChatGPT to self-driving cars, relies on Hinton’s backpropagation method. His contributions have not only shaped the AI revolution but have also established deep learning as the driving force behind artificial intelligence, cementing his legacy as one of the most influential figures in the field. But he would not stop there. More on the BigBang of AI later.
AI is Learning to be Human: The Evolution of Natural Language Processing
The ability of machines to understand and generate human language has become one of the most transformative advancements in technology. From chatbots handling customer inquiries and search engines refining queries in real time to Siri and Alexa, Natural Language Processing (NLP) has evolved into a critical driver of AI-powered communication. The goal: to allow machines to process, interpret, and respond to language in a way that is both meaningful and natural.
Its evolution began between 1960 and 1980 with the advent of rule-based systems, where linguists and programmers manually defined grammar rules and patterns, enabling computers to perform structured tasks but struggled with the complexity and ambiguity of language–think of the 1960s chatbot ELIZA. By the 1990s and 2000s, statistical methods replaced handcrafted rules, leveraging data-driven models like N-grams, Hidden Markov Models (HMMs), and Statistical Machine Translation (SMT) to improve accuracy, though they still lacked deep contextual understanding. The 2010s marked the deep learning revolution, with word embeddings like Word2Vec and GloVe capturing semantic relationships, while Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTMs) improved sequential data processing, while still facing challenges with long-range dependencies and computational demands.

1966 IBM Eliza — The First Chatbot — Pattern Matching & Ruled Based System

1997 IBM Deep Blue — Symbolic Search Algo
Transformers: The NLP Game Changer (2017–Present)
The true transformation in the NLP field came in 2017, when Google researchers introduced the Transformer architecture in their paper, “Attention Is All You Need.” Unlike RNNs, which are designed to process sequential data, Transformers process all words simultaneously, making them vastly more efficient and powerful. The introduction of self-attention mechanisms allowed models to weigh the importance of words dynamically, improving contextual understanding. Parallel processing enabled the simultaneous analysis of entire sentences, and positional encoding helped maintain word order without relying on sequential steps. This architecture became the foundation for today’s Large Language Models (LLMs) such as BERT, GPT (Generatice Pre-trained Transformer), and T5, which power advanced AI applications like text generation, translation, and summarization.
So how does it work? NLP breaks down language into structured data that computers can process, employing a range of sophisticated techniques to get the computer to comprehend:



The Big Bang of AI — AlexNet Algorithm
As GPUs revolutionized computational power in the early 2000s, artificial intelligence stood on the brink of a breakthrough. For decades, AI had been held back by limited computing power, which prevented neural networks from reaching their full potential. But by the early 2010s, three critical elements converged: advanced hardware, massive datasets, and improved algorithms. This set the stage for a seismic shift we are now living in — the moment AI would go from theoretical promise to practical dominance.
The Rise of Convolutional Neural Networks (CNNs)
One of the key breakthroughs came in 2012 the form of Convolutional Neural Networks (CNNs), a type of neural network designed to process visual data. Inspired by the human visual cortex, CNNs were pioneered by Yann LeCun in the late 1980s and early 1990s. Early CNNs were successfully used for digit recognition in banking and postal services, but they had a fatal flaw: they required vast amounts of labeled data and immense computing power — both of which were unavailable at the time.

By the early 2000s, CNN research had stagnated. The networks were promising but difficult to scale, and many in the AI community doubted whether deep learning would ever become practical. That all changed with two key developments: the rise of GPUs and the creation of ImageNet.
ImageNet: The Fuel for AI’s Takeoff
In 2009, Dr. Fei-Fei Li, a professor at Stanford, recognized AI’s biggest bottleneck: the lack of high-quality, large-scale labeled datasets. To solve this, she spearheaded ImageNet, a dataset of millions of labeled images across thousands of categories. More than just a collection of pictures, ImageNet provided the vast amount of data needed to train AI at an unprecedented scale.

Dr. Fei Fei Li
To push AI forward, she launched the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2010. The competition gave researchers a global benchmark, forcing them to build better image recognition algorithmic models. It wasn’t until 2012 that everything changed.

2012: AlexNet, the Inflection Point
For years, Geoffrey Hinton, the Godfather of AI, and creator of backpropagation, had championed deep neural networks, but mainstream AI research remained skeptical. That changed in 2012 when his student Alex Krizhevsky, along with Ilya Sutskever, trained a deep CNN using NVIDIA GPUs, which dramatically accelerated its learning process. The result was an CNN algorithm called AlexNet — a model that crushed its competition in the ImageNet challenge, cutting error rates nearly in half.

Geoffrey Hinton, Ilya Sutskever, and Alex Krizhevsky
AlexNet was different. It wasn’t just deep — it leveraged ReLU activations for faster training, dropout to reduce overfitting, and GPU acceleration to scale efficiently. This wasn’t an incremental improvement; it was a quantum leap. The impact was immediate. Tech giants, startups, and research labs pivoted toward deep learning overnight. NVIDIA, once focused on gaming, became the backbone of AI’s acceleration. From self-driving cars to medical imaging, deep learning was no longer a niche research topic — it was the future.
And so, the Big Bang of AI that was set to revolutionize society as we once knew it, had begun.

Large Language Models (LLMs): What They Are and How They Came to Be
The fusion of GPUs and AlexNet sparked an AI revolution and ignited an entire new field. By December 2015, this momentum led to the creation of OpenAI, a nonprofit AI research lab founded by visionaries like Elon Musk, Sam Altman, Ilya Sutskever, John Schulman, and Greg Brockman. Their mission was to ensure that artificial intelligence serves humanity’s best interests. From this initiative, ChatGPT was born. At its core lies the power of Large Language Models (LLMs) — deep learning systems trained on massive datasets to generate human-like text (think ImageNet + AlexNet + NLP). Today, LLMs form the backbone of modern AI, powering everything from virtual assistants to automated content creation and cutting-edge business intelligence tools.
The rise of LLMs was driven by a series of game-changing innovations. The most crucial was the Transformer architecture mentioned before, which was introduced by Google researchers in 2017. Unlike earlier models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks, which processed text sequentially and struggled with long-range dependencies, Transformers revolutionized AI with self-attention mechanisms and parallel processing. Older models often failed to connect words across long sentences — for example, in “I went to the store and bought apples. They were fresh and juicy,” an RNN might struggle to link “they” back to “apples.” Transformers, on the other hand, process the entire sentence at once, recognizing that “they” refers to apples, no matter how far apart they appear. This breakthrough made LLMs faster, more accurate, and vastly more powerful, unlocking new levels of contextual understanding and fluency in human language.



Estimating the Cost and Barriers to AI Development
Developing large-scale LLMs requires enormous financial and technological investment. Training a cutting-edge AI system on a 100,000-unit H100 GPU cluster demands $5.64 billion to $7.76 billion in capital expenditures. The bulk of this cost comes from hardware: with NVIDIA H100 GPUs priced at $30,000–$40,000 each, the GPUs alone cost $3 billion to $4 billion. Housing these GPUs requires 12,500 high-performance servers, adding another $125 million to $250 million. Additional computing resources, including CPUs, RAM, and other components, increase the total by $62.5 million.
Beyond hardware, infrastructure costs are significant. Networking and storage solutions alone add $450 million, while power and cooling systems — critical for managing the cluster’s estimated 150MW energy consumption — range from $1 billion to $2 billion. Constructing or retrofitting a data center could require another $1 billion. These figures exclude operational costs — electricity, maintenance, staffing, and software licensing — which could reach hundreds of millions annually.
With these astronomical costs, AI development remains the domain of well-capitalized tech giants. Beyond infrastructure, success in AI requires elite engineering talent, proprietary datasets, and cutting-edge optimization techniques that further consolidate power among a few industry leaders. While cloud-based AI services offer alternatives, their long-term costs remain prohibitively high.
In early 2025, the DeepSeek breakthrough challenged the assumption that training competitive LLMs requires multi-billion-dollar budgets. DeepSeek-R1 was trained over 55 days using 2,048 Nvidia H800 GPUs, with a direct training cost of about $5.6 million — far below industry norms. Yet, this figure excludes major expenditures such as hardware, infrastructure, and operations. The hardware alone is estimated at $70 million, with projected annual costs of $500 million to $1 billion. DeepSeek mitigated costs through efficient resource allocation, leveraging export-compliant Nvidia H800 GPUs, optimizing model architectures, and refining training methodologies. Deep Seek demonstrated that while large-scale AI remains capital-intensive, technical innovation and strategic optimization can dramatically lower costs, making high-performance models more attainable. A dynamic we will see unfold in the next few years, or months.
The State of AI Today
AI is transforming industries and pushing the boundaries of what’s possible. Generative Adversarial Networks (GANs) have become more stable, while diffusion models set new benchmarks in generative AI, producing hyper-realistic images, videos, and even molecular structures for drug discovery. Multimodal AI, capable of integrating text, images, audio, and video, is unlocking breakthroughs in both creative fields and scientific research.
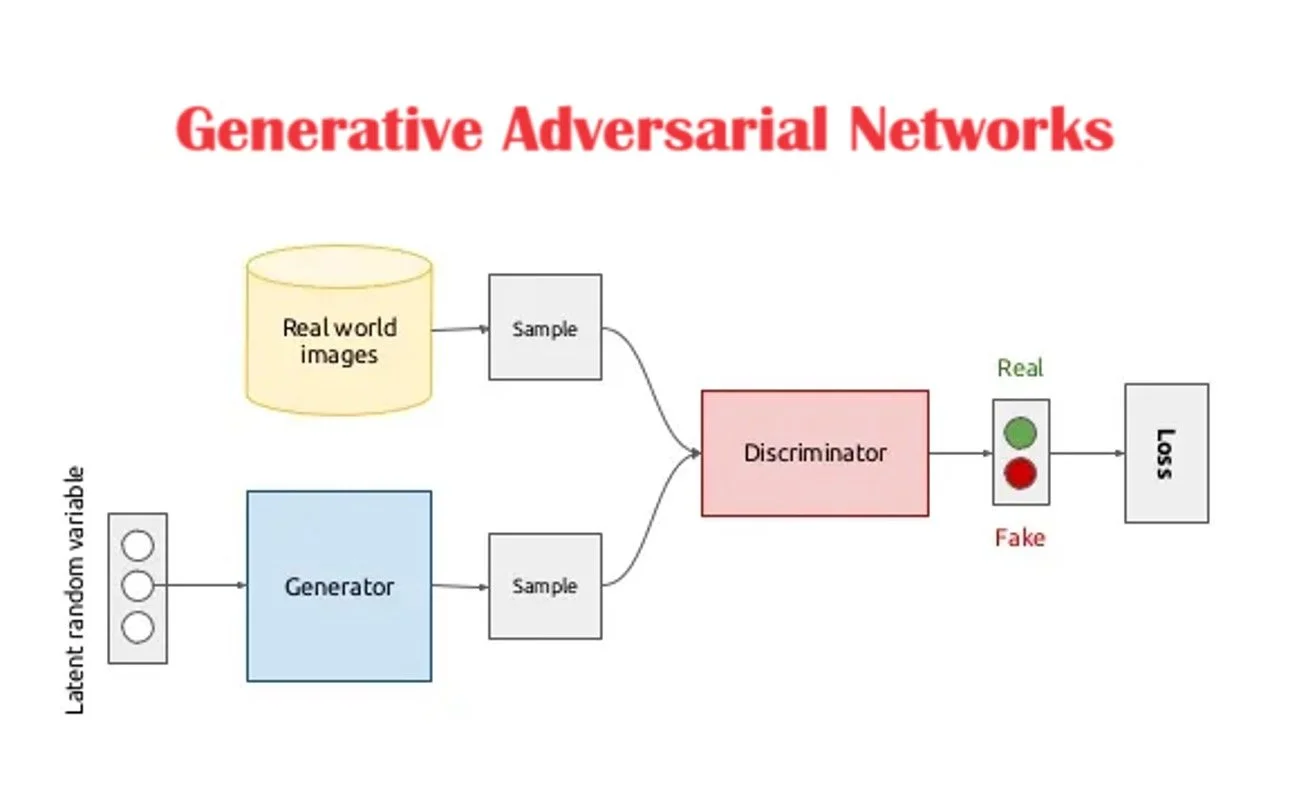

GANs — Machine Learning Models Used to Generate New Synthetic Data that Resembles Real Data (AI Instagram Models etc)
Meanwhile, Edge AI is pushing intelligence to the device level, reducing reliance on cloud computing while enhancing privacy and real-time responsiveness in autonomous systems and smart assistants. At the frontier, Quantum AI is gaining traction, with quantum-enhanced machine learning promising breakthroughs in optimization, cryptography, and materials science.
AI and robotics are converging, giving rise to more dexterous and adaptive machines, capable of solving real-world problems with unprecedented precision. As these technologies evolve, AI is no longer just about automation — it’s reshaping decision-making, creativity, and problem-solving, driving the next era of digital transformation.
AI in the Hudson Hill Portfolio
At BlueCloud, we are actively deploying AI into Fortune 500 businesses — not merely as a technological upgrade but as a fundamental driver of transformation and innovation. By leveraging the power of AI across our Hudson Hill Capital portfolio, we are unlocking unprecedented efficiencies, reducing costs, and enabling smarter decision-making at scale. From automating complex workflows to enhancing customer engagement through AI-driven insights, our approach accelerates revenue growth while optimizing operational performance. As breakthroughs in deep learning, computing power, and large-scale language models continue to push the boundaries of what’s possible, we remain at the forefront of innovation, ensuring our portfolio companies harness AI’s full potential to secure a lasting competitive edge in the digital economy.
Building on this overarching commitment to transformation, we are operationalizing artificial intelligence across our portfolio companies through BlueCloud’s artificial intelligence capabilities.
Take InXpress, for example — a global logistics franchise platform that empowers small businesses with enterprise-level shipping solutions. Here, we are deploying a conversational AI agent to automate franchisee support by retrieving knowledge base insights, summarizing support tickets, and scaling frontline service. In parallel, a natural language shipping chatbot enables customers to place orders using simple prompts — such as “I want to ship a 18x12x14 package from New York to London” — thereby transforming the experience from cumbersome, form-based interactions to intuitive, conversational engagement. With a three-month implementation and a $150K investment, this initiative is forecasted to deliver a 5.4x ROI through support cost savings and improved conversion, embodying our vision of AI as a catalyst for measurable business impact.
At Fusion Transport, a national 3PL logistics provider, our AI focus is on supercharging the inside sales function. Manual prospecting and fragmented customer systems were stalling growth. To solve this, we introduced AI web agents that scrape websites for high-fit leads, machine learning models that document transportation needs, and natural language generators that produce personalized emails, call scripts, and LinkedIn outreach at scale. We also layered in sentiment detection and complaint triage to strengthen post-sale customer management. This targeted, AI-driven sales enablement is producing measurable commercial lift — yielding a projected 6.5x return on the same $150K deployment.
Meanwhile, MarketTime, a digital sales enablement platform for wholesale commerce, is leveraging AI for intelligent revenue prioritization. With vast customer data trapped inside Tableau dashboards, sales teams struggled with analysis, forecasting, and lead targeting. Through predictive modeling, we’re translating data into action — ranking leads by conversion probability, surfacing the right next steps, and improving outbound sales performance through smarter segmentation. This initiative, also scoped at $150K over three months, is on track to return 4.5x the investment — driven by enhanced targeting, faster cycles, and increased close rates.
Across these efforts, AI is not a siloed experiment or a speculative investment — it is a functional, pragmatic accelerant of business value. Whether enhancing service, optimizing sales, or unlocking insight from data, we believe AI will define the next decade of enterprise growth. And we intend to lead from the front.
The Commercial Imperative: Continuous AI and the Battle for Advantage
Services companies like BlueCloud are needed to distill the hardware and software advances into commercial applications that business people require to increase revenue growth and reduce expenses. But realizing the full promise of AI requires more than just deployment — it demands discipline and the proper data foundation of their enterprise technology.
Without data, artificial intelligence models cannot train or deploy. Advances in technology and bandwidth have removed the historical constraints on data generation and consumption. Enabled by large public clouds like AWS, Azure, and GCP, the migration from client-server environments to multi-tenant, hosted software deployments has created centralized databases connected by low-latency bandwidth. These advances have unlocked the ability to store, retrieve, and act on data in real time — lifting data from static repositories into dynamic engines of intelligence.
Increased data utilization thus makes both humans and machines better at making predictions and solving problems. Customers, employees, and executives now expect real-time insights to power their decisions. As a result, data is no longer a back-office function — it now forms the core of modern products, services, and business operations.
However, enabling this kind of real-time intelligence requires a fundamentally different technology architecture than the one most businesses have today. Decades of legacy investment in on-premise infrastructure have left enterprises with fragmented, distributed systems that are ill-suited to the demands of modern AI. To remain competitive, especially against cloud-native disruptors, incumbents must migrate their legacy architecture — including core applications and databases — into centralized, cloud-first ecosystems. AI/ML models require data to move, just as internal combustion engines require oil. If data is stuck, intelligence can’t flow.
This is why companies must focus on building comprehensive, next-generation cloud data and analytics platforms. That means leveraging best-in-class platforms like Snowflake — which unifies compute, storage, and analytics in a single cloud-native architecture — alongside ecosystem tools such as Starburst, DataRobot, Dataiku, and ThoughtSpot to accelerate advanced AI and machine learning, all running on foundational cloud infrastructure like AWS, Azure, and GCP. Without this foundation, businesses will fall behind. The capabilities of their AI models will lag their peers, and the quality of their data will steadily decline.
Yet even once the right architecture is in place, the journey is far from over. AI is dynamic. Models perform well when trained, but performance inevitably decays. Customer behavior evolves. Markets shift. Data changes. To remain accurate and effective, AI models must be constantly maintained, refined, and retrained. This is the essence of what we call Continuous AI.
Continuous AI — is a strategic requirement for enterprise businesses. It’s the discipline of proactively monitoring deployed models, detecting and addressing performance drift, and continuously optimizing based on live data. Failure to do so can lead executives to believe AI has underdelivered, when in reality, the underlying infrastructure and processes simply weren’t designed to sustain it.
The challenges are many: concept drift (changes in the relationship between inputs and outputs), data drift (changes in the input variables themselves), and algorithm drift (where models become misaligned with evolving business needs). These issues are rarely visible in the short term — but over time, they compound. Without active oversight, models can become outdated and even harmful to decision-making.
BlueCloud has developed one of the few managed service solutions built specifically for this challenge. Our Continuous AI offering ensures that models stay current and effective, even as conditions shift. By constantly monitoring, recalibrating, and retraining models in production, we help our clients turn AI from a one-time project into a resilient, evolving business capability.
Looking ahead, one thing is clear: artificial intelligence, and data, will define the next era of business — not as science fiction, but as real-time operational execution. Cloud-native disruptors are already leveraging AI to build faster, leaner, more intelligent organizations. IDC projects that enterprise technology intensity will rise by nearly 50% over the next decade, driven by AI adoption and the shift to modern, data-driven infrastructure. In this landscape, next-generation architecture won’t be a competitive advantage — it will be a requirement. Companies that act now will unlock compounding gains across their operations. Those that delay risk falling permanently behind. The battlefield of the 21st century will be defined by artificial intelligence — not as science fiction, but as real-time operational execution. The companies that understand this shift — and build accordingly — will shape the future of every industry they touch.
The Future is Here!
Artificial intelligence is the continuation of a centuries-long pursuit to extend human cognition through machines. From Aristotle’s formal logic to Turing’s computational theories, from GPUs and TPUs to today’s dynamic LLMs, AI reflects the relentless evolution of thought, hardware, and algorithmic ingenuity. But its future will not be shaped by theory alone — it will be shaped by execution. At Hudson Hill and BlueCloud, we believe the true promise of AI lies in its application: in how we reimagine workflows, augment decisions, and architect data platforms that sustain continuous intelligence. The next generation of industry leaders will not be those who simply adopt AI — but those who understand it, operationalize it, and continuously evolve it. We are building for that future — where intelligence is not static, but living; not confined to code, but embedded across the enterprise; not a concept, but a competitive advantage.
—
Isabela Umaña Costa
View the original article here.